Behind the gate: The reality of a refinery turnaround
Key Highlights
-
Refinery turnarounds require planning 12–18 months ahead; disciplined scoping prevents cost and schedule overruns that derail shutdown performance.
-
Clear coordination of labor, materials, permits and training before shutdown protects day-one readiness and keeps execution on schedule.
-
Execution is short but high-risk; strong communication, contingency planning and tool readiness help manage hidden faults and sequencing conflicts.
-
Post-turnaround reviews capture discovery work, cost drivers and safety lessons to improve scope rules and planning for the next outage cycle.

Imagine your facility’s population surging from 300 to over 2,000 people overnight. This is the reality you face during a refinery turnaround – a high-intensity period where a single day of delay can run into millions and, in some industries, erase a year’s profitability.
The pressure is most visible during execution, but the schedule is shaped much earlier. Success depends on a rigorous five-phase framework that begins over a year before the first valve is turned and doesn't end until the final lessons-learned review is complete.
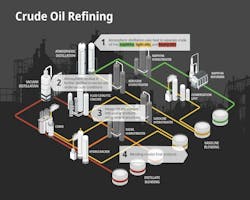
What happens during a refinery turnaround?
A refinery turnaround is a planned, comprehensive shutdown that typically takes place every three to five years. During the turnaround, units come offline for weeks so teams can do work that can’t be done safely on a running plant. That work spans statutory inspections and integrity checks through to repair and changeout jobs, upgrades, and the testing that proves systems are ready to restart.
Between shutdowns, punch lists grow as underperforming assets and offline-only tasks stack up behind limited redundancy. This is why scope discipline during a refinery shutdown matters financially. AP-Networks’ data suggests cost/schedule outcomes swing hard when scope isn’t held: more than two-thirds of turnarounds miss plan by 10% on cost and schedule (or trip after startup), and 40% see overruns or delays above 30%.
This five-phase view helps you see where that uncertainty is created, and where it can be reduced.
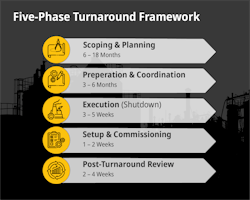
The five-phase turnaround framework
To keep scope, cost, and restart risk under control, it helps to break a refinery turnaround into five phases (see Table 1). Each phase has its own constraints – what must be defined, what must be verified – so the challenges and unexpected issues will change as you move through each phase.
|
Phase |
Primary Objective |
Typical Duration (Months/Weeks) |
|
Phase 1: Scoping and planning |
Define clear scope and budget |
6–18+ months |
|
Phase 2: Preparation and coordination |
Coordinate teams and allocate resources |
3–6 months |
|
Phase 3: Execution |
Perform planned maintenance tasks |
3–5 weeks (1–4 weeks minimum) |
|
Phase 4: Startup and commissioning |
Ensure safe operational restart |
1–2 weeks |
|
Phase 5: Post-turnaround review |
Document lessons learned and update strategy |
2–4 weeks |
Phase 1: Scoping and planning. Scoping and planning start 12–18 months out. Here you build the job list in full: routine inspection and compliance work, known underperforming assets, deferred fixes that can’t be tackled online, and any capital changes that have crept onto the horizon.
You also start defining what “done” looks like – technical requirements, acceptance criteria, access constraints, and which tasks will sit on the critical path. At the same time, you fold in preventive and predictive work that’s been waiting for the outage, and outage a start stress-testing labor requirements and budget against what the scope is really asking for.
On sites that run flat out for long periods, that list can grow quickly between outages. Consider a refinery that has operated 24/7 for five years. By the time the outage arrives, the turnaround scope is rarely a neat bundle of discrete jobs. It’s a backlog of “we’ll do it when we can” work – items that touch shared systems, require isolation, or need specialist checks.
Converting that backlog into defined work packages and mapped dependencies soon clarifies which tasks will govern the schedule. However, even with disciplined scoping, not every task is visible before the outage. Some work only surfaces after equipment is opened, which is why most teams protect the critical path with a defined contingency in the schedule.
Phase 2: Preparation and coordination. Once the scope is locked, preparation turns the scope into a Master Turnaround Plan (MTP). Work packages get sequenced. Isolation points, access, permits and sign-offs get mapped. Procurement moves from “we’ll need this” to delivery dates that have to hold. EPC partners often sit at the center of that coordination, shaping contractor mobilization and what arrives on site, and when.
At this point, labor ramps up. A site can swell from a few hundred people to several thousand, so safety stops being a set of reminders and becomes a system: induction, permit-to-work discipline, clear rules for energized work and confined spaces, and consistent supervision. You’re also reserving the windows for asset checks that depend on isolation – valve testing, alignment with equipment decoupled, instrument verification, electrical inspections with gear de-energized – so they don’t end up fighting for space later.
A common trouble spot in this phase is the late realization that a specialist scope item needs training and verification planning. For example, a specialist flow measurement package may be in scope, but crews may not yet be prepared to install, calibrate, and verify it. When spool-piece assemblies are custom and delivery windows are tight, teams often need to schedule multiple pre-turnaround site visits and training, so the work package doesn’t stall once the shutdown clock starts.
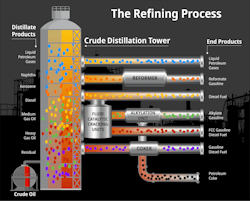
Phase 3: Execution. Execution is the shortest phase, but it carries the most exposure. The shutdown clock is running, work fronts are stacked on top of each other, and the plan is only as good as the next sign-off. Day-one readiness matters here. If access isn’t clear, isolation isn’t complete, or a critical tool isn’t available, the delay rarely stays local. It pushes into the jobs behind it.
On site, you’ll see electrical, mechanical and instrumentation teams moving in parallel, with OEM support brought in to install, test, verify or replace components as needed. The single biggest success factor is steady communication – clear handovers between crews, fast escalation when something doesn’t match the work package, and a shared view of what’s driving the day’s sequence. Verification equipment becomes part of that risk picture too; if a tester fails or a calibration can’t be completed, you need a way to keep the work moving.
Unexpected issues still appear. Labor assumptions can be wrong. A hidden fault shows up once equipment is opened. Sequencing conflicts surface. As one of my colleagues once put it, “Every battle plan is perfect until it meets the enemy.” Again, this is why it pays to plan for the unplanned by building contingency into the schedule.
Phase 4: Startup and commissioning. Startup is where the risk concentrates. You’re bringing systems back online at temperature and pressure, often after invasive work, and the tolerance for uncertainty drops sharply. The refinery’s internal fire crew is often staged and ready during this window, because the consequences of a missed line-up or incomplete checks are serious.
The restart is also sequenced. Utilities are energized first, then the early process units come back to establish stable feed for what follows. Each successful step unlocks the next, so a problem that looks small on one unit can stall everything downstream.
This is where verification earns its place. Before introducing hydrocarbons, you’re checking valve positions against procedures, confirming instrument loops and calibration where required, validating electrical conditions after re-energization, and doing walkdowns for leaks, missed blinds, or anything that doesn’t match the work package. In the United States, OSHA’s Process Safety Management standard formalizes this logic through the pre-startup safety review requirement after certain changes.
Phase 5: Post-turnaround review. Once the plant is back in steady operation, the turnaround isn’t finished. In the post-turnaround review, you capture what actually happened while it’s still fresh: which work packages were incomplete and why, where rework appeared, what drove cost variances, and which safety controls held up under pressure. Leadership tends to focus on the schedule drivers and the overruns, because those are the levers that decide whether the next shutdown is tighter or looser.
A big part of that discussion is discovery work – repairs triggered by inspection and Non-Destructive Testing (NDT) results, “as-found” conditions once equipment is opened, and rework where the field reality didn’t match the work package. The point is to understand why that discovery work wasn’t visible earlier (limited access on a running unit, incomplete asset history, optimistic assumptions) and how to reduce it next time.
These reviews often surface OEM-specific improvement areas, such as delivery timelines and safety feedback. The value is practical: turn the findings into processes changes people will see next time – updated scope rules, clearer acceptance checks, earlier procurement triggers, and tighter handovers.
Five questions to stress-test your next turnaround
Use these questions to spot schedule and startup risks early:
- Scope: Have you locked the work that genuinely needs an outage, and separated it from “nice to do if we have time”?
- Dependencies: Do your work packages reflect the real constraints – isolations, access, permits, sign-offs – and the tasks that sit on the critical path?
- Readiness: Are long-lead items, specialist tooling and training in place early enough to protect day-one execution?
- Startup proof: Before hydrocarbons return, what are the specific checks you will complete and who signs them off – valve line-ups, instrument verification, electrical conditions, leak walkdowns?
- Learning loop: After startup, how will you capture what slipped, why it slipped, and what will be changed before the next outage?
Inside the refinery gate, the best turnarounds are the ones that eventually become forgotten – quiet, predictable, and devoid of drama. That silence is the signature of a five-phase discipline that refuses to leave your organization’s safety or profit to chance.
About the Author
Frederic Baudart
CMRP
Frederic Baudart, CMRP, serves as the Global Product Manager at Fluke, where he leads the Process Instrumentation Tools product line. With more than 29 years of industry experience, he brings deep expertise in service engineering, maintenance and reliability, software solutions, and X-ray technologies. Baudart has held key leadership roles across sales, product management, marketing, and service operations at renowned organizations including Fluke and GE. He is a frequent speaker at conferences and a published author of numerous technical articles and case studies featured in global trade publications. Baudart is certified in Thermal/Infrared Thermography Level II, and earned technical degrees in electrical and instrumentation engineering from a respected technical college in Belgium.