Is CMMS condition monitoring right for you?

When senior management’s eyes turn to the shop floor in search of ways to push through more production and squeeze out further savings, maintenance management should be prepared to respond.
The maintenance department has many tools at its disposal for improving the return on company assets, including Lean Maintenance, better use of computerized maintenance management systems (CMMS), and a host of three-letter acronyms such as total productive maintenance (TPM), reliability-centered maintenance (RCM) and root cause analysis (RCA).
One area of greatest potential for companies with extensive capital assets is to integrate these tools with condition monitoring of critical assets. Efforts to tighten communications of condition-monitoring instrumentation and data analysis software with CMMS and automation infrastructure, combined with the proliferation of wireless sensor systems and the drive to reduce manpower skill and time requirements, are bringing implementation costs down and drawing much attention to this approach.
But the considerable investment necessary to purchase and implement these technologies isn’t always cost-effective. Is it time you started, broadened or automated your foray into condition-based maintenance (CBM)? Here are seven steps to determine whether and how to proceed with a CBM program:
Step 1: Understand your options
Although CBM might seem like the answer to all your problems, unfortunately, it’s not that easy. In many cases, CBM isn’t necessary because the consequences of a run-to-failure approach are so minimal. For example, most people change the light bulbs when they fail because monitoring the filament resistance of every bulb in your plant is a much more costly alternative. Similarly, you wouldn’t send oil samples from your car engine to be analyzed in a lab on a regular basis (i.e., condition based maintenance), because simply changing the oil every 7,500 miles is more economical.
So there are three alternative approaches:
- Failure-based maintenance (FBM): An asset is run until it fails, at which point it’s repaired or replaced. Depending on the asset, this approach can be hugely economical (e.g., light bulbs), or highly expensive or even life-threatening (e.g., large rotating equipment).
- Use-based maintenance (UBM): An asset is maintained on a periodic or metered basis such as every three months or 10,000 gallons of use. In some cases, this is a more economical approach than FBM, i.e., when the consequences or cost of running equipment to failure are higher than the cost of the UBM program.
- Condition-based maintenance (CBM): Triggers are established that correlate to impending equipment degradation or failure. When these conditions are identified through periodic inspections, defensive actions are taken, such as repair or replacement of a part, to pre-empt the failure just in time (Figure 1).
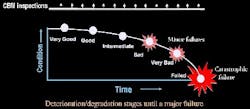
Knowing when to use FBM, UBM and CBM is a matter of understanding the costs, benefits and risks associated with each approach. Every component of each piece of equipment must be examined individually and as an integrated system to determine the consequences of each possible type of failure and the cost/benefit of each maintenance approach to deal with that failure. This can be a lot of work for most companies with hundreds if not thousands of systems, assets and their individual components, which may explain why many if not most companies have defaulted to a firefighting mentality that favors the FBM approach.
Step 2: Maintenance strategy - the big picture
Before diving into the murky waters of establishing a CBM program, it’s important to stand back and develop a proper context, sense of priority and justification for the expense associated with condition-based monitoring. By developing a maintenance strategy, you’ll set longer-term goals, objectives, performance measures and targets, and action items for achieving your targets. The maintenance strategy provides the big picture of everything that needs to be in place to meet your organization’s needs, which ensures that the CBM program has the greatest probability of success.
For example, perhaps certain regulatory pressures or a pressing HR issue such as high maintainer turnover need to be addressed immediately. If these issues aren’t addressed before implementing a CBM program, then there may be a much higher risk of failure. The maintenance strategy ensures that competing and complementary priorities are understood, and action items properly integrated.
Step 3: Focus on your critical assets
Once a maintenance strategy has been developed, and assuming CBM was identified as a priority, the next step is to identify your critical assets. Conducting a criticality analysis of your systems, equipment and components avoids the overwhelming workload of determining the best maintenance approach for each and every asset. A critical asset can be defined as one for which a failure would cause catastrophic consequences, such as:
- A key bottleneck in the process (e.g., if this asset is down the entire line will be down)
- A severe health and safety-related failure (e.g., failure of this component may cause an explosion that would threaten human life)
- A costly customer impact (e.g., if we can’t manufacture a certain product on this asset, we can’t deliver on time, and we stand to lose our largest customer)
- An expensive and time-consuming repair (e.g., a long period of production downtime required to repair, expensive replacement parts difficult to source, highly specialized external skills required)
Sensitivity analysis can determine which assets are more sensitive to failure, for example, asking, “What is one minute of uptime worth in terms of marginal revenue and maintenance cost avoidance?” Many CMMS packages have analysis tools that can help pinpoint critical assets and components, at least in terms of historical maintenance costs for each asset. If technicians have been using problem, cause and action codes accurately and in sufficient detail, then even more useful data is available to determine, say, the top 10 most costly root causes for every asset in the plant.
Suppose this kind of report reveals that bearing failure of a certain type accounts for 20% of maintenance costs in this facility. In turn, this data can be used to build a business case for implementing a CBM program that incorporates vibration analysis. Some of the more sophisticated packages have more comprehensive analysis tools, such as RCM, which gives users more detailed analysis of how a given component or asset might fail, the cause or failure mode, the result of failure or failure effect, the likelihood or risk of occurrence, and the quantified criticality of failure or impact.
Step 4: Conduct failure analysis on critical assets
Once you compile a prioritized short-list of critical assets/components, follow the steps below. Here, the example is a cooling water system that might have catastrophic consequences if the water isn’t maintained within a given temperature range.
- Determine operating context for the asset being analyzed: e.g., cooling water system maintains water at 40 F to 45 F continuously.
- Define the functions of the asset: e.g., maintain water temperature and contain water in the tank.
- Assess possible failures: e.g., water too hot or too cold.
- Identify possible failure modes or (root) causes: e.g., heat exchanger fouled, shutoff valve closed, or pump bearing fatigued.
- Determine the most probable failure effects for each failure mode: e.g., inefficient heat exchanger results in higher utility cost, extra cooling tower sections in operation, and eventual inability to deliver quality parts.
- Propose an appropriate maintenance task for each failure mode that mitigates the risk of failure (i.e., using failure history, probability and costs to compare financial and technical feasibility of failure-based, use-based or condition-based actions): e.g., monitor heat exchanger efficiency (Table 1).
|
Technology |
Application |
Approaches |
| Vibration - used on rotating equipment such as motors and turbines |
|
|
| Lubrication |
|
|
| Infrared |
|
|
| Ultrasonic |
|
|
|
Laser |
|
|
After completing the first six steps in this article, you’ll see that CBM might or might not be the most cost-effective solution. If the consequences for a given failure mode are catastrophic, and the probability of occurrence high, CBM can probably be cost-justified. If the failure has little or no impact, then a failure-based maintenance program is likely the optimal solution. Similarly, a use-based maintenance program might be cost-effective if the impact of failure is offset by instituting a simple time- or meter-based routine. The cost/benefit trade-off for CBM is discussed in more detail that follows.
Step 5: Determine the required level of sophistication and cost
The cost of a CBM program stems from four main sources – data collection, data analysis, workflow and maintenance policy or action taken:
Data collection: Most CMMS packages are capable of collecting condition-based data either manually keyed, batch loaded from handheld devices, or fed on an online real-time basis from process automation equipment. The incremental cost to you depends on a number of factors such as:
- How often you will need to collect the data (i.e., inspection frequency)
- How detailed the data needs to be
- The level of certainty of the data collected (e.g., data may be in the form of a probability curve or within a range as opposed to point data)
- Whether the production equipment will need to be down while collecting data
- The level of automation required for the desired level of timeliness and accuracy, from manual inspection to handheld devices to an automated feed from sensors
- The skill level of maintainers that are collecting the data
- Whether your current CMMS is capable of capturing the data in the manner desired
The cost is therefore a mix of internal or external labor plus any hardware and software used to collect the data.
Collected data is monitored and analyzed to look for condition indicators such as a condition reading outside the acceptable upper or lower control limits, an unacceptable trend in terms of direction or slope, a level of inconsistency or variability that is outside an allowable range, or a correlation or relationship to other condition indicators (e.g., if both temperature and pressure are elevated by more than 10%).
Data analysis can be expensive depending on the level of sophistication required. Several specialized services will analyze data from the more popular CBM technologies as described in Table 1, such as vibration data, oil samples, and so on. A number of vendors are performing somewhat less sophisticated analysis of data such as roof and road conditions. However, much of the CBM data can be analyzed using today’s more comprehensive CMMS software (see sidebar, “Advanced CBM features.”)
Once data is collected and analyzed, and a trigger occurs, there’s a need for workflow: notification, approvals, alarming, initiating an automated control loop, launching a work order, reporting and so on. Most modern CMMS packages accommodate these in at least a simplified manner. However, a few packages have sophisticated graphical workflow engines, business intelligence and extensive integration capability with process automation, which gives comprehensive capability in this area.
For example, users can track, in real time, the state of condition indicators from SCADA or process automation equipment on the shop floor using dashboards within the CMMS. Thus, if sensors detect that a given piece of equipment is down, or the pressure inside a component is trending outside an allowable range, users can drill down on a graph such as presented in Figure 2. In turn, this gives users the ability to determine the root cause and take action, or automate the response based on user-defined business rules.
Workflow: To identify the cost of your workflow, you must consider the level of sophistication required, and your current environment. If you have process automation equipment and a CMMS with the previously described capabilities, and the two worlds are properly integrated, then you have only the cost of configuration and implementation (which isn’t necessarily trivial). Those of you just looking to get started on CBM for a few critical assets can manage with much less sophistication – a CMMS with basic notification and reporting capability, and a human interface with process automation.
Maintenance policy or action taken: – Based on an alarm, report, notification, etc., maintainers must take action to alleviate the condition. Sample actions are opening a valve, repairing or replacing a component, conducting a preventive maintenance routine or performing a complete overhaul. To determine the best response, technicians require access to current and historical information. CMMS packages vary tremendously in this regard, although most allow users to at least access equipment history records for the assets in question.
Some packages can determine if similar problem codes were used and, if so, what were the corresponding cause codes, subsequent actions taken, and correlation with other variables such as equipment vendor or tradesperson responsible for the work. This lets users recognize recurring patterns such as a batch of faulty parts from one manufacturer, or improper worker training. A few packages have extensive RCM, RCA, incident-reporting and failure-analysis capability, which not only assist in determining immediate action, but allow users to adjust the longer-term maintenance policy regarding a given asset. For example, adjustments can be made to:
- Inspection frequency for each component
- When inspections aren’t necessary (e.g., when component is new or just after major overhaul)
- Type of inspection performed
- Skill level of inspector
- Failure modes and effects
- Risk of failure
- Condition indicators that represent a given stage of deterioration for a component or asset
- Actions or tasks required at each stage of deterioration, such as a given minor maintenance routine, major overhaul, minor repair, or major repair
- Preferred list of part and component vendors
- Technician skills required for any of the actions above
In this way, as historical data is compiled over time, the CBM program can be optimized starting with one or a few critical assets done well and expanding from there. Having a sophisticated software tool is a major plus to this end, and there are many vendors emerging that specialize in this area. In my view, the preference is for software that can be integrated from shop floor automation, to the CMMS, and on to higher-level management support systems.
From a cost perspective, there’s a huge dollar range for the options described. For those companies that don’t have the sophisticated software tools, start with a spreadsheet for each of the few critical assets under review, and record the output from your failure analysis (see Step 4, “Conduct failure analysis on critical assets”). Almost all CMMS packages have the capability to develop standard tasks or PM routines that can be triggered at least manually, based on the results of an inspection. Fine tune your maintenance policies using this spreadsheet and whatever historical data is collected through the CMMS.
As you become more sophisticated in your use of CBM, you should look at upgrading your CMMS, or at least purchasing the specialty software tools that improve on incident reporting; collecting and analyzing failure data; and recording failure modes, effects, condition indicators, etc. Some of these software tools have established partnerships with one or more CMMS packages.
Note that some companies use subcontractors to implement maintenance policies, i.e., the workflow software alerts a maintenance planner or dispatch desk function within your company, and a subcontractor is summoned to take action. In some cases, alerts are sent directly to the subcontractor. Using a subcontractor is cost-effective compared to hiring full-time internal resources when specialized skills are required for only short periods of time throughout the year.
Step 6: Determine the potential savings
Once you understand the cost side of the business case, identify the benefits from implementing a CBM program. This is what excites management as to the potential cost reduction and revenue enhancement opportunities. The business case must provide sufficient comfort that any additional cost over current failure-based or use-based maintenance is warranted. Some key measures typically used in cost justifying CBM are discussed below (see sidebar, “Sample cost/benefit analysis”).
Asset availability: By monitoring asset condition rather than letting them run to failure or conducting periodic preventive maintenance, you can maximize critical equipment uptime or availability. For example, monitoring the vibration of rotating equipment allows you to pinpoint the optimal time for performing maintenance. This avoids a long period of downtime if you wait for failure, or spending excessively on premature or unnecessary preventive maintenance. With greater asset availability comes greater production throughput. For some large asset-intensive industries, even a 0.1% increase in throughput amounts to millions of dollars annually in increased revenue.
Performance: Equipment is designed to work at an optimal level of performance. Over time, equipment performance might decrease from deterioration of components or parts. CBM can detect this deterioration before it affects performance. Equipment vendors can be helpful in understanding the predictors of deterioration. What would be your incremental gain in production output for a 1% increase in performance, i.e., the equipment working at its engineered peak performance?
Reliability: CBM improves asset reliability measures such as mean-time-between-failure and mean-time-between maintenance because it replaces guesswork and reliance on statistical norms for how often equipment is supposed to fail or be maintained. For example, by monitoring the level of particulates in your lubrication, you’ll likely be able to improve on a statistic-based PM program to change the oil once every 1,000 hours. This also assumes the approach of letting it run to failure results in more costly consequences than the cost of implementing CBM (e.g., higher repair costs plus greater downtime).
Quality of output: One of the success measures most often overlooked in justifying a CBM program is the increased consistency and quality of production output. As a given asset deteriorates, it can continue to run with the same availability, at the same level of performance, and as reliably as ever, however, it may be producing lower quality product. This can be minimized by monitoring the quality of the product and determining predictors of this type of asset deterioration, so that maintenance on the equipment can be done before any quality problems surface.
Total cost of ownership: Another typical driver for implementing a CBM program is reducing the total cost of ownership for a given asset. When the cost of implementing CBM is offset by the savings from less catastrophic unplanned downtime, less frequent inspections or reduced preventive maintenance, the resultant asset lifecycle cost or total cost of ownership will be lower.
Spare parts inventory: Because monitoring asset condition gives you a longer planning horizon as to when spare parts may be required, typically, companies find that less inventory is required on hand “just in case.”
Environmental, health and safety: As regulatory pressures grow for so many industries, success measures around environmental impact and employee health and safety continue to increase in importance. Measures such as energy consumption, greenhouse gas emissions and lost-time accidents can be tracked and correlated to the condition of assets. For example, as equipment degrades over time, it might consume more energy and operate less efficiently, such as burning a greater volume of fuel and exhausting more pollutants. Predictors of this degradation can be monitored and it can be prevented, resulting in significant savings to the environment, avoidance of regulatory penalties, and reduced utility costs.
7. Understand the cultural change
In reading through this article, the two key concepts that should jump out at you are planning and discipline. For those who are used to playing the hero firefighter who leaps to the rescue of operations and solves one maintenance issue after another, implementing CBM brings about a major change in culture. First, there’s a lot of work upfront in planning: determining critical assets, conducting failure analysis, choosing an appropriate maintenance policy, and so on. Second, you can see from the level of detail involved in this work that discipline is essential.
A third cultural change for some companies is the increased level of interaction required among operations, engineering and maintenance. The three departments must become actively involved through sharing knowledge (e.g., assets, process, product, and operating environment), coordinating activities (e.g., scheduling asset downtime) and tracking results. Even operators can be involved in the process through training on what to monitor during their shift, such as the sounds of excessive vibration, the feel of excessive heat, or the sight of equipment that appears misaligned. Some observations by operators may warrant a simple adjustment, while others may require a call to maintenance.
So, if you’re looking for a successful CBM program implementation , and you’re trying to break through some tough cultural barriers, keep the following base principles in mind:
- Think big, but start small and simple; i.e., think strategy, but start with a small group of critical assets using manual or semi-automated processes
- Highlight a compelling reason why people should change, i.e., the business case, but do not promise what you aren’t prepared to deliver
- Involve key stakeholders, including operators that work with critical assets – the greater the participation, the greater the buy-in
- Select a champion for the program who is well respected, has decision-making capability and has skin in the game
- Conduct a pilot implementation for one critical system or asset for proof of concept and to gain track record
- Don’t skimp on training
About the Author

David Berger
P.Eng. (AB), MBA, president of The Lamus Group Inc.
David Berger, P.Eng. (AB), MBA, is president of The Lamus Group Inc., a consulting firm that provides advice and training to extract maximum performance, quality and value from your physical assets, processes, information systems and organizational design. Based in Toronto, Berger has held senior positions in industry, including for two large manufacturers, and senior roles in consulting. He has written more than 450 articles on a variety of topics such as asset management, operations management, information technology, e-commerce, organizational design, and strategy. Contact him at [email protected].