The operator's guide to successful troubleshooting
One of the most important traits that process operators can have is the ability to quickly and accurately diagnose process upsets and respond accordingly. They do this using their eyes and ears coupled with the knowledge they’ve gained from experience and the systems they have available to facilitate troubleshooting. An operator’s eyes are extended by the process information that the instrument and control system (ICS) provides and facilitated by the ICS design and built-in intelligence. The operator’s experience can be expanded through operational group intelligence, tribal knowledge (knowledge passed on from other operators past and present), and the operational knowledge base of experience retained in the ICS.
Troubleshooting is an art, but a good portion is a learned skill, which is enhanced by experience and operator capability. A good operator will work at developing troubleshooting skills and abilities. A good troubleshooter is worth his or her weight in gold to a company.
Also, perhaps surprisingly, many companies have noted that increased use of automation has not necessarily resulted in a reduction in the operator workforce. This is due at least in part to the fact that many operational jobs have evolved from involving mostly routine, repetitive tasks to focus largely on process troubleshooting.
Troubleshooting
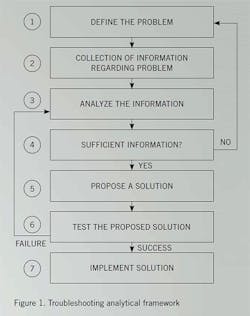
A general analytical model for troubleshooting is illustrated in Figure 1.
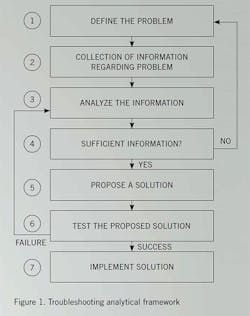
Step 1, defining the underlying problem to troubleshoot, can sometimes be difficult because processes are big, complicated, and interconnected with various material and energy balances. The troubleshooting process commonly starts with a process alarm, which alerts the operator that the process has exceeded a predefined process limit, such as a high process level, pressure, or temperature. The alarm’s cause may be unclear: For example, a low-level alarm in a vessel may sound, but the problem could be rooted in the feed to the tower and involve a problem in the tank farm.
Step 2 involves the collection of process data (current and the immediate previous history), which the operator will turn into useful information based on his or her overall situational awareness. The operator’s situational awareness is essentially the operator’s mental process worldview. Here is where the ICS can help by providing online alarm troubleshooting assistance, designed to diagnose the problem based on commonly known alarm causes and suggest remedial procedures and guidance. The ICS will have a number of capabilities that should be used to their fullest extent to help the operator troubleshoot process problems. The ICS must provide factual, reliable, and trustworthy data and present the process data in consistent, concise, and useful manner. It is important to determine that there really is a problem and what it is.
Step 3 involves analyzing the data to find a root cause and to determine whether there is sufficient information to propose a solution to the process problem. Case-based reasoning initially tends to dominate the analysis. Case-based reasoning is based on the whether the operator has seen the problem or something similar before. This typically leads to the operator to try the previously employed solutions. The downside is that the operator may not think the problem through, and the proposed solution may waste resources or makes the problem worse. This is not to say that past experience is not valuable, but some cognitive thought processes should be applied before jumping in, or the operator may jump from the frying pan into the fire.
Logical analysis typically starts with the big picture and works to narrow perspective into smaller pieces to be analyzed to identify what is causing the problem. If the problem’s big picture is easily divisible, divide the problem in half and determine which half still has the problem, and then divide again until the problem’s cause is identified and a solution is proposed.
One key question is whether something has changed in a process or in a piece of equipment’s operation. The change can be sourced to a human (e.g., a valve is operated in error, controls have been changed; the production rate has changed, etc.) Alternatively, it may be sourced to a nonhuman factor. Look for potential changes such as feed rate or composition changes from outside the plant, cooling medium changes, steam supply variation, tower flooding, exchanger clogging, ambient changes (e.g., changes in ambient temperature, rain, lightning, etc.), or anything that doesn’t look normal.
Developing a time line from when the process went off normal can be valuable in identifying when equipment failed or when a change may have occurred.
Step 4 is deciding whether sufficient information exists to propose a solution to the identified problem. If the answer is “no,” return to the data-gathering of Step 2.
Step 5 is proposing a solution to the process problem.
Step 6 is testing the solution. If the test is successful, the problem is solved. If not, we go back to Step 3 to see where the analysis went wrong. In the event that more than one seemingly viable solution is proposed, the operator must decide which to try first. Typically, potential solutions are tried in order of their estimated likelihood of fixing the problem. However, other factors may dictate the order in which solutions are tried: Safety, ease of application, cost, resource demands, and personal choice all can tip the scales in favor of one potential solution being tried before another.
Step 7 is implementation of the solution. If the conventional troubleshooting method comes up short, alternatives can be tried. One is to draw an imaginary circle around the problem area, noting all process and energy flows that cross the imaginary circle and then examining these flows to determine whether they can cause the problem. A second method is to look at the energy and mass balances to see if they will give you a clue. The third method, which is essentially fault insertion, is to manipulate your process simulation to see if you can simulate the problem.
First principles are also used to gather information and troubleshoot problems. For example, the level principle states that inlet less the outlet flow equals the rate of accumulation. Conservation of mass and energy, gas laws, and the thermodynamic laws are further examples. If the simple level principle had been applied to the 2005 BP Texas City Isom tower, the accident would have likely been prevented.
Process troubleshooting challenges
While operational troubleshooting and equipment troubleshooting share some similar thought processes, one of the major differences between troubleshooting failed equipment and process operational troubleshooting is the time frame. The first challenge is to come up with an actionable time frame for solving the problem with the information available to the operator.
It is desirable that the troubleshooting, repair, and return to service of failed equipment occur in a timely manner, but this lacks the immediacy of troubleshooting operational problems where time is money. Time delays in troubleshooting and responding to process upsets often will result in an escalation in the severity of the process upset, which can lead to a developing hazard, and in the worst case to a safety incident.
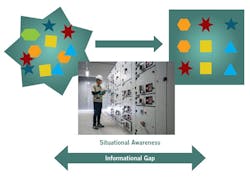
This requires the operator to be able to identify the problem quickly and act to resolve it so that the problem does not escalate and result in a negative outcome. The operator must be trained and experienced in the operation of the process. For the operator to recognize the problem and gather information, he or she must have a clear situational awareness of the current and immediate past state of the process. The ICS plays an important part in reliably presenting the process data to the operator in a clear and concise manner. The informational gap between the presentation of the ICS data and the operator’s situational awareness is illustrated in Figure 2. Situational awareness is key to troubleshooting operational problems. What the operator or process engineer knows and when it becomes known are key to nipping process problems in the bud. Situational awareness is defined by two key aspects.
First is the process data as measured and indicated by the ICS and how it is presented to the operator. Poor presentation means poor situational awareness. The Abnormal Situation Management Consortium (ASM) is a good resource on DCS graphics and abnormal situation management, which can help the operator during troubleshooting.
The second aspect is the operator’s process worldview – essentially a gestalt of all of the process information coming into the operator. The operator’s worldview is dependent on his or her training, experience, and capabilities. Problems not conforming to their worldview will require a shift in their thinking and approach, which some operators may have difficulty with, especially if the problem gets too far from normal operation. Learning to move past case-based reasoning in troubleshooting will develop the operator’s troubleshooting skills. Case-based reasoning can sometimes lead to confirmation bias, which is a common cognitive bias wherein the operators will believe they know what is causing the problem, and seek only information that confirms that bias while ignoring contrary information. This can lead to wasted time and resources and an inability to solve the problem without accessing outside help.
Knowing when to seek outside help is a key skill in troubleshooting. The plant process engineer and the plant shift foreman are key resources for troubleshooting process problems. Other support personnel, such as a process reliability engineer, technical and maintenance service personnel, quality control personnel, and process development scientists, can also be a great help. Online video conferencing capability can provide real-time interaction with process experts outside of the plant to assist in process troubleshooting. Many times the outside help does not solve the problem but helps the operator in doing so by contributing a different perspective. Attending HAZOPs and LOPAs can help an operator or process engineer look at the process in a different way and view how analysis of hazardous conditions occurs; this can support the use of different troubleshooting methods when a similar issue arises.
Process alarms (not status alarms) are one of the means by which the process control system notifies the operator that there is a potential problem. Too many alarms (alarm flood) are detrimental to determining what is going on, as it blurs situational awareness. This was a contributing factor in the Three Mile Island accident. Alarm rationalization, which involves reducing the number of alarms, is one technique for reducing the risk of alarm flood, but it can be overdone.
The outside operator also plays a vital role in troubleshooting a process. In the early days, board operators often went out to conduct a visual and audible check of the process. With today’s centralized control room commonly located a good distance away from the process, board operators have become more “video-game operators,” frequently poorly “grounded” in the process.
In addition, many companies make their inexperienced operators field operators and then “promote” them after a while to being board operators. Field operators are the eyes and ears of the board operator, and the key principle is “when in doubt, verify,” so there should be sufficient local instrumentation for the field operator to be able to locally monitor process levels, temperatures, and pressures. It is also helpful to have local (and easily readable) indicators on all important process transmitters. Further, the ability to monitor furnace and heater flames should be provided.
I once asked a very senior operator (a 30-year employee) what was the first thing he did when he determined that there might be a process problem. His answer was, “Make sure my instruments aren’t lying to me.” This may seem facetious, but many safety incidents have resulted from poorly maintained, failed, inoperative, or unavailable instruments. Examples include the BP Texas City incident in 2005, the Puerto Rico Cataño oil refinery fire, and the Tosco Martinez Hydrocracker explosion. In the BP Texas City incident, a high level in a raffinate splitter was a primary cause. In this case, the differential-pressure-level transmitter was not providing the correct level because the level was above the transmitter’s upper tap, changing the differential-pressure-level transmitter into a specific gravity meter. Further, the level sight gauges were not functional, and the high-high level alarm (float type) had not been tested correctly and was nonfunctional. This is an indication of how dependent the operator is on the instruments operating correctly while troubleshooting process problems. When a process abnormality is detected, always verify that the instruments are reflecting reality. A key to quickly solving process problems is a reliable instrumentation system that the operators trust. If the operators do not trust the instruments, how can they have a valid situational awareness of the problem?
An effective technique to help the operators “trust” their instruments is, if sufficient online sensors exist, to include online models continuously calculating material and/or energy balances of the ongoing process. If all flow and other relevant sensors are working correctly, for example, then a sufficiently “closed” material balance should exist. If the accuracy of a material balance does not meet specifications, then the root cause is likely to be a faulty sensor, and the ICS interface can be designed when a material balance fails to list a faulty sensor as one of the first items for an operator to check.
Many of the possible causes of the problem may not be immediately detectable with relevant sensors; that’s when the problem’s cause cannot be automatically reduced to a single probable cause. Here, an online checklist and troubleshooting charts in the ICS of the possible causes as well as additional troubleshooting guidance and some indication of the probability of their occurrence and/or the priority for checking them out are helpful. The failure modes and effects analysis (FMEA) methodology can be used to provide analysis to help develop the troubleshooting checklist, troubleshooting charts, alarm procedures, and troubleshooting guidance. The FMEA methodology can be applied directly to ongoing difficult process and equipment problems.
For safety-critical alarms, the alarm procedure should be online in the ICS and be short and concise – for example, it should specify that no more than 10 troubleshooting steps be taken before a safety action takes place to bring the process to a safe state. All regular process alarm and status indications should have written procedures that provide troubleshooting guidance for the alarm.
The future
Interactive troubleshooting assistance will be available from the ICS to guide the operator through the troubleshooting process. The operator HMI will continue to evolve to provide more information in different formats through the uses of augmented, mixed, and virtual-reality interfaces. Many of these interfaces will be portable, going where the operator goes. For example, augmented-reality safety glasses can let the field operator look at vessels and see levels, pressures, and temperature profiles or at furnace flames and see various shapes of flames and what they signify. Virtual reality could be used to “see” simulations and their real-time counterparts or present the health of the plant in virtual ways. Operators could virtually fly over the plant, dipping down to look at process variable and equipment status and conditions to quickly troubleshoot problems.
Deep machine learning and artificial intelligence will enhance the ability to troubleshoot operational and maintenance problems and may reside in the ICS or in the cloud, where more data may be available if the process instrumentation is IoT-enabled. Initially these programs will reside on the control system and will provide assistance to the operator in operating the process and troubleshooting problems in the process. These programs will migrate to portable devices that will serve as operator personal assistants (with roots in current personal assistants such as Siri, Alexa, and Cortana) that boast the equivalent knowledge base of a senior operator who has the operational history of the plant (all the good and bad things) as well as real-time connection to the process with machine learning capabilities.
Conclusions
In troubleshooting process problems and upsets, the operator has a tough job, because modern process plants typically are large, have high throughputs, and process hazardous materials. They have many interconnections and potentially are integrated into larger facility processes. The experience, training, and capability of the operator are key to having a successful troubleshooting experience. The operator must also have a clear situation awareness of the developing problem, and the ICS must present reliable data in a clear, unambiguous manner. Poorly presented data will lead to poor operator situational awareness. A poorly designed or maintained ICS will lead to inefficient and unsuccessful troubleshooting.
William (Bill) L. Mostia, Jr. P.E., is principal engineer at WLM Engineering Co. Contact him at [email protected].
Unfortunately, the design of how the ICS presents its information is typically based around the P&ID. While there’s nothing inherently wrong with this, the overall presentation may not be designed to help the operator troubleshoot problems in a timely manner. Alarms are typically geared to alert the operator when a process variable exceeds a process limit or a safety limit. Often, the number of alarms generated can vary from many to too many. ISA has developed ISA Standard ANSI/ISA-18.2-2009, “Management of Alarm Systems for the Process Industries,” that has been published both as the national standard (ANSI/ISA 18.2) and the international standard IEC 62682. This standard covers all key aspects of alarm management, including alarm rationalization. The alarm rationalization process focuses on determining the several attributes of alarm configuration (e.g., set point, priority, class, type, deadband, time delay) and may not include looking at alarm presentation from a troubleshooting perspective; this may have implications for the operator’s situational awareness and ability to troubleshoot efficiently.
The ICS systems has the ability to help facilitate troubleshooting by providing online alarm and process troubleshooting procedures, additional troubleshooting guidance with troubleshooting checklist and charts, and in some cases, interactive troubleshooting help. Looking ahead, artificial intelligence and deep machine learning will enhance the ICS’s ability to help operators do their job and quickly and efficiently troubleshoot any process problems that develop.
Acknowledgement: Bill Mostia Jr. thanks Dr. Joseph Alford for his input on this article.